K-means clustering algorithm
다음 예에서는 KMeans 클러스터링 및 Centroid 함수가 데이터 세트에 적용되는 실제 사용 사례를 보여줍니다. KMeans 함수는 데이터 포인트를 유사성을 공유하는 클러스터로 분리합니다. KMeans 알고리즘이 구성 가능한 반복 횟수에 걸쳐 적용됨에 따라 클러스터는 더욱 컴팩트해지고 차별화됩니다.
KMeans는 다양한 사용 사례의 다양한 분야에서 사용됩니다. 클러스터링 사용 사례의 몇 가지 예로는 고객 세분화, 사기 탐지, 계정 이탈 예측, 클라이언트 인센티브 타겟팅, 사이버 범죄 식별, 배송 경로 최적화 등이 있습니다. KMeans 클러스터링 알고리즘은 기업이 패턴을 추론하고 서비스 제공을 최적화하려는 경우 점점 더 많이 사용되고 있습니다. 위키백과 참조
KMeans 함수 적용 사례
Qlik Sense KMeans and Centroid functions
Qlik Sense는 유사성을 기준으로 데이터 포인트를 클러스터로 그룹화하는 두 가지 KMeans 함수를 제공합니다. KMeans2D - 차트 함수 및 KMeansND - 차트 함수를 참조하세요. KMeans2D 함수는 2차원을 허용하며 산점도 차트를 통해 결과를 시각화하는 데 적합합니다. KMeansND 함수는 3개 이상의 차원을 허용합니다. 표준 차트에서는 2D 결과를 개념화하기 쉽기 때문에 다음 데모에서는 2차원을 사용하여 산점도 차트에 KMeans를 적용합니다. KMeans 클러스터링은 표현별 색상 지정을 통해 시각화할 수 있습니다. 또는 이 예에 설명된 대로 차원을 기준으로 합니다.
Qlik Sense centroid 함수는 클러스터에 있는 모든 데이터 포인트의 산술 평균 위치를 결정하고 해당 클러스터의 중심점 또는 중심을 식별합니다. 각 차트 행(또는 레코드)에 대해 centroid 함수는 이 데이터 포인트가 할당된 클러스터의 좌표를 표시합니다.
KMeansCentroid2D - chart function , KMeansCentroidND - chart function 차트함수를 참조
사용 사례 및 예시 개요
다음 예제에서는 시뮬레이션된 실제 시나리오를 단계별로 진행합니다. 미국 뉴욕주의 한 섬유회사는 배송비를 최소화해 비용을 줄여야 한다. 이를 수행하는 한 가지 방법은 창고를 유통업체에 더 가깝게 이전하는 것입니다. 이 회사는 뉴욕주 전역에 118개의 유통업체를 고용하고 있습니다. 다음 데모에서는 운영 관리자가 KMeans 기능을 사용하여 유통업체를 5개의 클러스터된 지역으로 분할한 다음 중심 기능을 사용하여 해당 클러스터의 중앙에 있는 5개의 최적 창고 위치를 식별하는 방법을 시뮬레이션합니다. 목표는 5개의 중앙 창고 위치를 식별하는 데 사용할 수 있는 매핑 좌표를 찾는 것입니다.
데이터 세트
데이터 세트는 실제 위도 및 경도 좌표를 사용하여 뉴욕주의 무작위로 생성된 이름과 주소를 기반으로 합니다. 데이터 세트에는 id, first_name, last_name, 전화, 주소, 도시, 주, 우편번호, 위도, 경도 등 10개의 열이 포함되어 있습니다. 데이터 세트는 로컬로 다운로드한 다음 Qlik Sense에 업로드하거나 데이터 로드 편집기를 위해 인라인으로 업로드할 수 있는 파일로 아래에서 사용할 수 있습니다. 생성되는 앱의 이름은 Distributors KMeans 및 Centroid이고 앱의 첫 번째 시트 이름은 Distribution Cluster Analysis입니다.
sample data file: DistributorData.csv
Distributor dataset: Inline load for data load editor in Qlik Sense
Title: DistributorData
Total number of records: 118
KMeans2D 함수 적용
이 예에서는 DistributorData 데이터세트를 사용하여 scatter plot 차트 구성을 보여주고 KMeans2D 함수를 적용하며 차트에 차원별로 색상을 지정합니다.
Qlik Sense KMeans 함수는 DeD(depth difference))라는 방법을 사용하여 자동 클러스터링을 지원합니다. 사용자가 클러스터 수를 0으로 설정하면 해당 데이터 세트에 대한 최적의 클러스터 수가 결정됩니다. 그러나 이 예에서는 num_clusters 인수에 대한 변수가 생성됩니다(구문은 KMeans2D - 차트 함수 참조). 따라서 원하는 클러스터 수(k=5)는 변수로 지정됩니다.
1. 새로운 앱을 생성하고 첨부된 DistributorData.csv를 적재합니다.


2. 클러스터 수를 지정하는 변수를 선언하고 정의에 5를 입력합니다. (vDistClusters) 시트편집에서 좌측하단에 변수 아이콘을 입력합니다.

3. 스캐터 차트를 생성하고 제목을 입력합니다. (Distributors)
4. 버블을 위한 차원에 id 선택, 측정값에 Avg([latitude]) , Avg([longitude]) 입력


5. 모양 -> 색상 및 범례 -> 색상 -> 사용자 지정 -> 차원 기준 선택
6. 차원 선택 표현식에 다음 표현식 입력 및 영구 색 체크
표현식 : =pick(aggr(KMeans2D(vDistClusters,only(latitude),only(longitude)),id)+1, 'Cluster 1', 'Cluster 2', 'Cluster 3', 'Cluster 4', 'Cluster 5')
레이블 Cluster ID 입력


테이블 차트 추가: Distributors
관련 데이터에 빠르게 액세스할 수 있도록 테이블을 준비하는 것이 도움이 될 수 있습니다. 산점도 차트에는 참조용으로 해당 유통업체 이름이 포함된 테이블이 추가되어 있지만 ID가 표시됩니다.
1. 테이블 차트 생성하고 id, first_name 및 last_name 필드를 차원으로 끌어옵니다.

막대 차트 추가: 클러스터당 observations #개
창고 유통 시나리오의 경우 각 창고에서 서비스를 제공할 유통업체 수를 아는 것이 도움이 됩니다. 따라서 각 클러스터에 할당된 배포자 수를 측정하는 막대형 차트가 생성됩니다.
1. 막대차트를 생성하고 제목을 # observations per cluster 입력
차원 표현식 : =pick(aggr(KMeans2D(vDistClusters,only(latitude),only(longitude)),id)+1, 'Cluster 1', 'Cluster 2', 'Cluster 3', 'Cluster 4', 'Cluster 5')
레이블 : Clusters
측정값 : =count(aggr(KMeans2D(vDistClusters,only(latitude),only(longitude)),id))
레이블 : # of observations
2. 모양 -> 색상 및 범례 -> 색상 -> 사용자 지정 -> 차원 기준 선택
표현식 : =pick(aggr(KMeans2D(vDistClusters,only(latitude),only(longitude)),id)+1, 'Cluster 1', 'Cluster 2', 'Cluster 3', 'Cluster 4', 'Cluster 5')
영구색 체크

Centroid2D 함수 적용
잠재적인 창고 위치에 대한 좌표를 식별하는 Centroid2D 함수에 대한 두 번째 테이블이 추가되었습니다. 이 표는 식별된 5개 유통업체 그룹의 중앙 위치(중심 값)를 보여줍니다.
1. 테이블 차트 생성 및 제목을 Cluster centroids 입력
2. 차원 : pick(aggr(KMeans2D(vDistClusters,only(latitude),only(longitude)),id)+1,'Warehouse 1','Warehouse 2','Warehouse 3','Warehouse 4','Warehouse 5')
3. 측정값1 : only(aggr(KMeansCentroid2D(vDistClusters,0,only(latitude),only(longitude)),id))
4. 측정값2: only(aggr(KMeansCentroid2D(vDistClusters,1,only(latitude),only(longitude)),id))

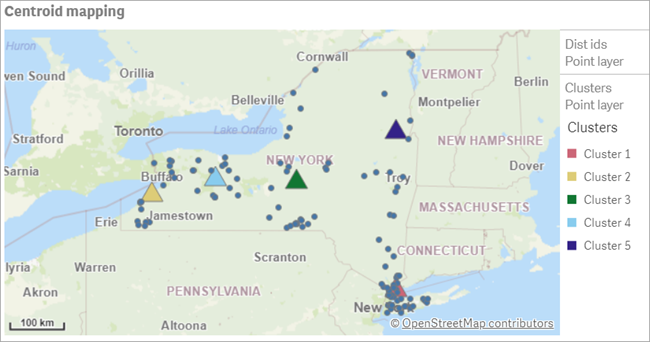
Centroid mapping
다음 단계는 중심을 매핑하는 것입니다. 시각화를 별도의 시트에 배치하는 것을 선호하는지는 앱 개발자에게 달려 있습니다.
1. 맵 차트 생성. 제목 : Centroid mapping
2. 레이어 -> 레이어 추가 -> 포인트 레이어 선택
3. 포인트 : id 선택
4. 위치 : 위도 및 경도 체크

1. 크기 및 도형에서 거품크기 작게 조정
2. 새로운 포인트 레이어 추가 생성
포인터 표현식 : =aggr(KMeans2D(vDistClusters,only(latitude),only(longitude)),id)
레이블 : Clusters
3. 위치 표현식에서 위도 및 경도 필드 체크
위도 표현식 : =aggr(KMeansCentroid2D(vDistClusters,0,only(latitude),only(longitude)),id)
경도 표현식 : =aggr(KMeansCentroid2D(vDistClusters,1,only(latitude),only(longitude)),id)
4. 색샹 : 차원기준 선택 표현식
=pick(aggr(KMeans2D(vDistClusters,only(latitude),only(longitude)),id)+1,'Cluster 1','Cluster 2','Cluster 3','Cluster 4','Cluster 5')
결론
이 실제 시나리오에 KMeans 기능을 사용하여 유통업체는 유사성을 기준으로 유사한 그룹 또는 클러스터로 분류되었습니다. 이 경우에는 서로 근접합니다. Centroid 함수는 5개의 매핑 좌표를 식별하기 위해 해당 클러스터에 적용되었습니다. 이러한 좌표는 창고를 건설하거나 찾을 초기 중심 위치를 제공합니다. 중심 기능은 맵 차트에 적용되므로 앱 사용자는 주변 클러스터 데이터 포인트를 기준으로 중심의 위치를 시각화할 수 있습니다. 결과 좌표는 뉴욕주의 유통업체에 대한 배송 비용을 최소화할 수 있는 잠재적인 창고 위치를 나타냅니다.
Map 차트에서 2개의 포인트 레이어를 사용하여 표현합니다.
Map 차트에 대한 자세한 설명은 다음 글을 참조하세요.
https://qliksense.tistory.com/185
클릭센스 지도에 차트 표시 (Map Chart)
지도에 위치 표시 지도에 위치를 표시하기 위해서는 위도. 경도의 좌표를 갖고 있는 데이터가 있어야 합니다. 다음 예제와 같은 데이터를 활용하겠습니다. 시트 편집에서 맵 차트 생성 시트 ->
qliksense.tistory.com

정보계 분석의 성공요소는 데이터 품질입니다.
데이터 품질에 대한 자세한 내용은
https://qliksense.tistory.com/195
데이터 품질관리 솔루션 (QDQM)
데이터 품질(Data Quality) 및 중요성 데이터 품질(Data Quality)이란? 데이터 품질은 데이터 세트가 정확성, 일관성, 신뢰성, 완전성 및 적시성에 대한 확립된 표준을 충족하는 정도를 평가합니다. 높은
qliksense.tistory.com
https://qliksense.tistory.com/196
데이터 품질관리 구축사례
QDQM이란? QDQM : Quick Data Quality Management 입니다. 마스터 테이블을 분석하여 데이터 타입 및 포맷, 길이속성, 문자속성, 논리속성을 파악합니다. 검사할 테이블의 필드를 프로파일링하여 필드의 데
qliksense.tistory.com
'Qlik Sense 개발가이드' 카테고리의 다른 글
| 문자열 함수 사용사례 및 Word Cloud (1) | 2023.12.01 |
|---|---|
| 데이터 관리자를 이용한 데이터 적재 (0) | 2023.11.30 |
| 클릭센스 데이터 정제 (중복 레코드 제거) (1) | 2023.11.29 |
| 클릭센스 피벗테이블에서 줄 바꿈 (0) | 2023.11.12 |
| Qlik Sense IntervalMatch (날짜간격에 조인) (1) | 2023.11.04 |



